Long before AI was being used to generate videos and code programs, it was being used to understand spoken language and take action on it. AI is the reason you can chat to Alexa, Siri, and Google Assistant and get these apps to do your bidding.
These same algorithms can help you create digital transcripts from audio files containing speech, whether these files are meetings, interviews, lectures, or just voice notes you’ve recorded for yourself. Transcripts give you a written record of what was said, and can be easily searched.
Big-name transcription services such as Rev and Happy Scribe only offer a limited amount of transcription free of charge, but you can get the job done without paying anything courtesy of Whisper. This is the speech-to-text engine developed by OpenAI (of ChatGPT fame), and there are no limits on using it.
You’ve got the choice of using a web version of the app hosted at Hugging Face, which is convenient but often busy at peak times. You can also choose to install the software locally on Windows—this means faster transcriptions, but you’ll need a decent PC to cope with the AI processing demands.
Whisper on the web

Head over to Whisper on Hugging Face, and you can get audio transcribed for free right in your browser—you don’t even need to register for an account. You have the option of uploading an audio file from your computer, or you can record speech directly into the app if you’ve got a microphone connected. Bear in mind that your audio may be used to further train future AI models–as is often the case, the privacy policies of OpenAI and Hugging Face aren’t clear on this.
To upload and process an audio file:
- Open the Audio file tab.
- Choose Click to Upload.
- Select an audio file.
- Check the Transcribe box.
- Click Submit.
After a few moments (or more), you’ll see the text output on the right of the screen. Processing times vary depending on the length of your audio file, and how busy the Hugging Face servers are. As this is a free service open to all, it’s also very popular,so you might find yourself waiting quite a while for files to get through the queue.
Within the interface you’ll find a few useful tools. Click the little pen icon just above the audio playback bar, for example, and you can trim down the start and the end of the clip—handy if you need to cut out silences or unimportant sections of the audio.
You can also switch to the Microphone tab to record some audio directly into the Whisper interface, or switch to the YouTube tab and get transcriptions from any video. Just paste in the video URL and you’re ready to go. It’s worth noting that YouTube already automatically adds transcripts to some videos, which can be found in the comments sections.
Whisper on Windows
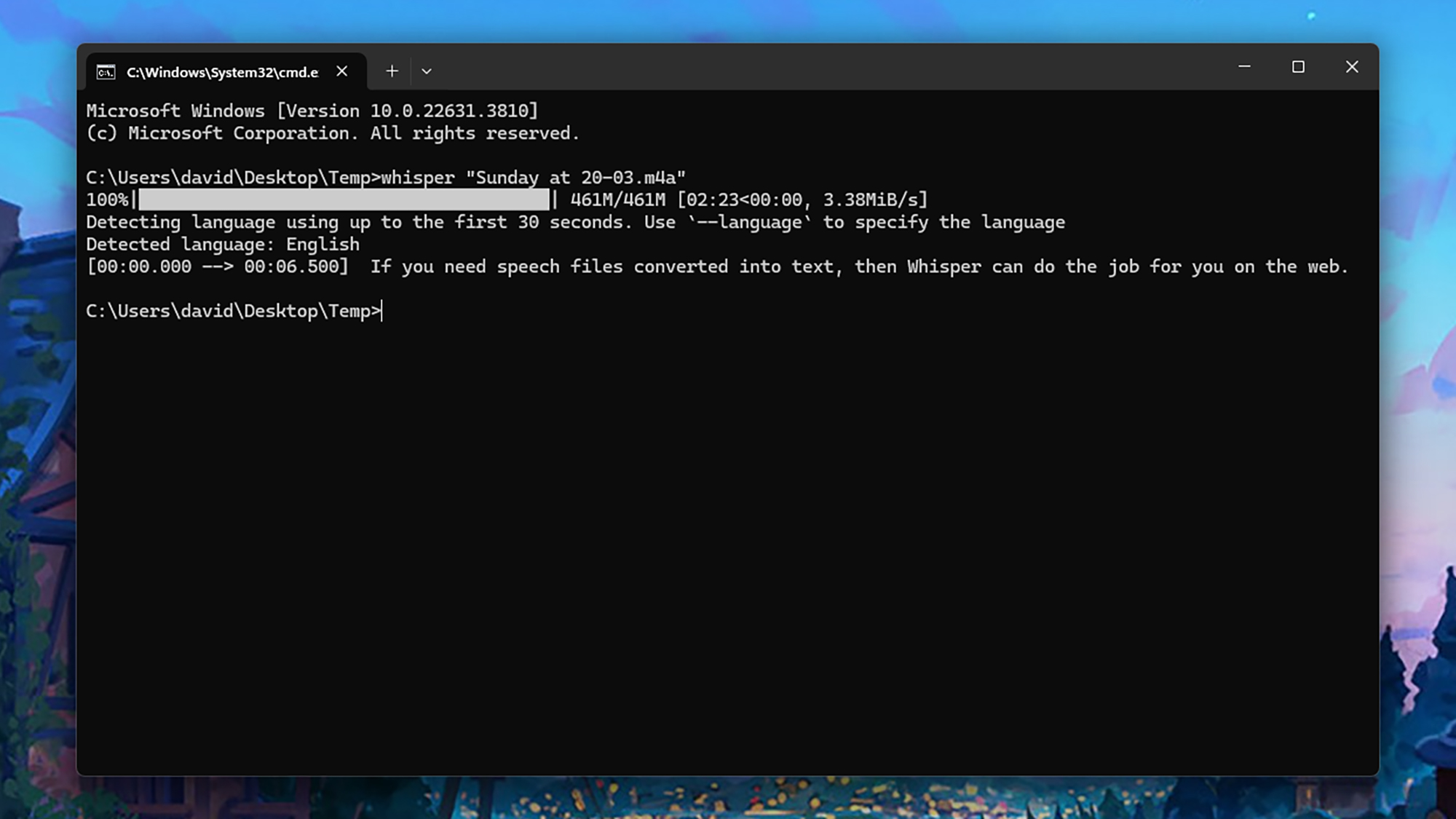
If you’re hitting a lot of delays in the Whisper web app, or you just want to keep your transcription processing more local and private, you can set up the AI model on a Windows computer. You need a CUDA-capable graphics card installed (see here for a list), with at least 4GB of VRAM, to handle the processing—if you’ve got a fairly recent Nvidia card installed, it’ll probably qualify.
This process is a lot more involved, and doesn’t give you much in the way of a user interface, so it’s not for everyone. It does have the advantages we’ve already mentioned though, and you’re not going to be stuck in a queue waiting for your files to be handled. It’s also a cool little project if you like tinkering around with code and programs.
Assuming your computer meets the grade, you need to get some bits installed on your computer: Python for the coding (make sure Add python.exe to PATH is checked during the installation), PyTorch for the machine learning libraries, Chocolatey for managing software packages, and FFmpeg for audio processing. They all come with installation instructions on the relevant websites, if you need them.
You’re then ready to install Whisper itself: Search for “cmd” on the Start menu and open Command Prompt, then type “pip install -U openai-whisper” and hit Enter. When the installation has finished, you can transcribe files like this:
- Open the folder with your audio files in File Explorer.
- Click on the address bar at the top, type “cmd”, and press Enter.
- Type “whisper”, then a space, then the name of your audio file.
- Hit Enter again, and the processing starts.
The text is displayed on screen, and saved as a series of text files in the same folder as the audio. If you need to convert multiple files at the same time, just list them all after the “whisper” command, separating each one with a space.
Even if you’re not familiar with Python or the command prompt, you shouldn’t have too much trouble getting everything up and running. There are plenty of guides online that can help if you need assistance. This is one of the best tutorials out there, taking you step-by-step through each stage, and explaining some advanced functions available to you (like swapping to a different AI model).
The post How to transcribe text for free using AI appeared first on Popular Science.
from Popular Science https://ift.tt/FU2A6Kp







0 Comments